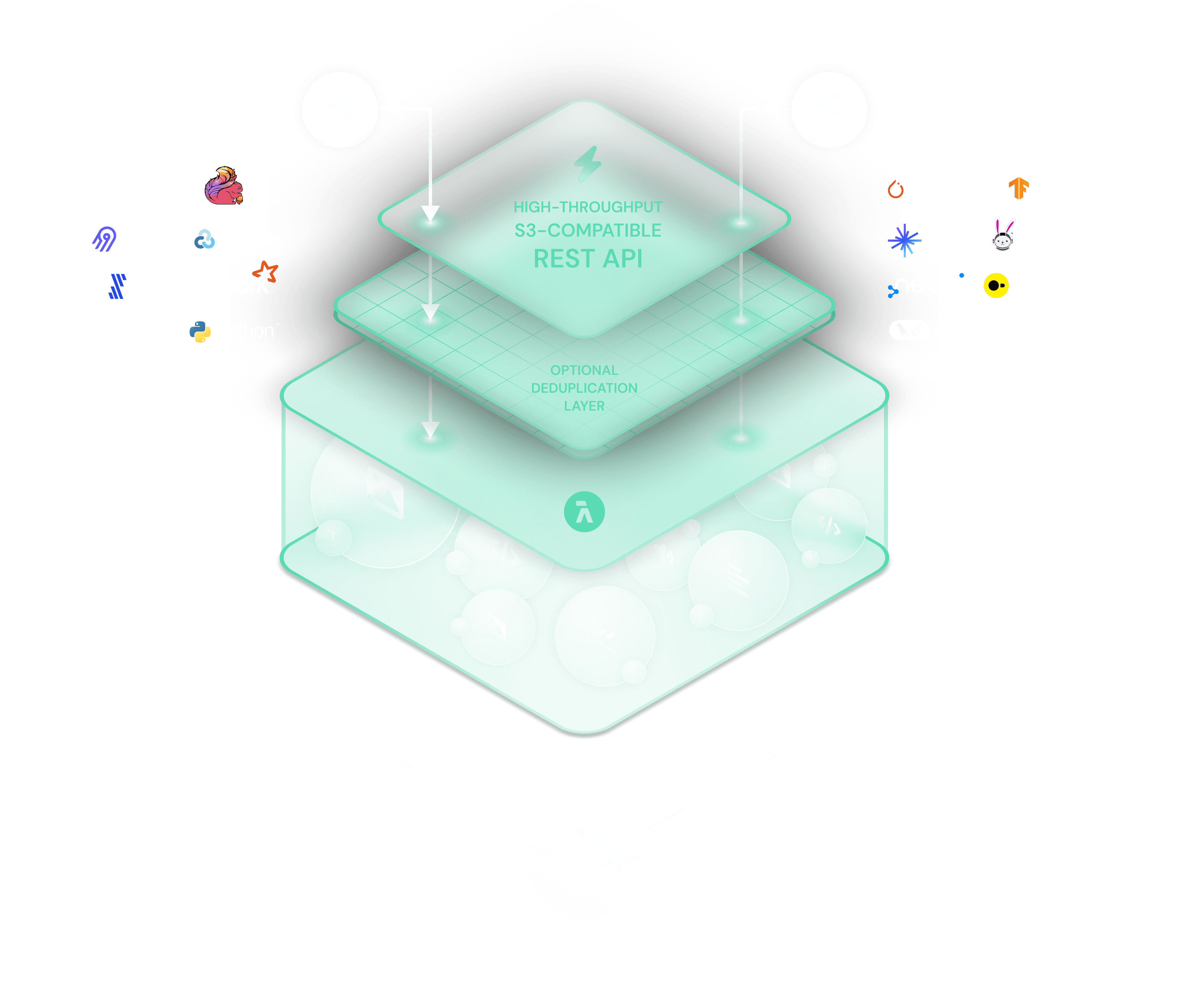
Serve unstructured documents and source content with high throughput.
In modern RAG pipelines, vector embeddings are served from vector databases; the underlying unstructured data (PDFs, web pages, markdowns, knowledge base articles) still resides in object storage.
UltiHash accelerates RAG systems by enabling:
Works with Zilliz, LanceDB, Chroma, or custom RAG pipelines
Ideal for hybrid cloud setups where data locality matters
Avoids egress costs by colocating with compute or caching layer